안녕하세요
chatGPT가 출시된지 벌써 1년이 흘렀습니다.
그리고 my GTPs 가 나오면서 그 활용 범위가 무지막지하게 넓어지는 중입니다.

분명 오류투성이인데다가 한글은 잘 알아듣지도 못하고, 특히 한국 관련한 내용들은 오점 투성이였던 chatGPT가
이제는 실시간 검색기능까지 추가되면서 거의 정답만을 말하고 있습니다.
chatGPT가 추천해주는 논문도 이제는 정말로 있는 논문이며, 심지어 이미지도 만들어 주고 있죠.
이제 인공지능이 우리 삶에 깊숙하게 침투했다는 것은 모두 인정해야 합니다.
그래서 저도 chatGPT 활용 영역을 조금씩 넓히려고 공부중입니다.
그래서 오늘의 이야기는..
<chatGPT를 활용한 딥러닝 예제코드 만들기>
chatGPT는 질문을 어떻게 하느냐에 따라 답변이 달라지기 때문에, 질문이 매우 중요합니다.
그래서 프롬프트 엔지니어라는 직업이 새로 생기기도 했죠.
하지만 고차원적인 질문 이전에 매우 간단하게만 질문을 해봤습니다.

그리고 아래 파이썬 코드가 나옵니다.

딥러닝 예제 코드
<아래 코드를 복사하세요>
# 필요한 라이브러리를 불러옵니다
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.losses import SparseCategoricalCrossentropy
# MNIST 데이터셋을 불러옵니다
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 데이터를 정규화합니다
train_images = train_images / 255.0
test_images = test_images / 255.0
# 모델을 구성합니다
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10)
])
# 모델을 컴파일합니다
model.compile(optimizer='adam',
loss=SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 모델을 훈련시킵니다
model.fit(train_images, train_labels, epochs=5)
# 모델을 평가합니다
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\n테스트 정확도:', test_acc)
위 코드는 TensorFlow/Keras 를 사용한 모델 구축 및 훈련과정을 통해 아래 단계를 거쳐 딥러닝을 실행하는 예제입니다.
1. 필요한 라이브러리를 불러온다.
2. MNIST 데이터셋을 불러와 훈련 세트와 테스트 세트로 분류한다.
3. 데이터를 0과 1 사이의 값으로 정규화하여 신경망에 적합하게 만든다.
4. 간단한 신경망 모델을 구성한다.
위 예제에서는 Flatten 레이어로 시작하여 두개의 Dense 레이어를 사용한다.
5. 모델을 컴파일하고 훈련시킨다.
6. 테스트 세트에서 모델을 평가하여 정확도를 확인한다.
코드 실행해보기
이제 저 코드를 어떻게 실행해 보기 위해 Colab으로 들어갑니다.
colab.google
Colab is a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs. Colab is especially well suited to machine learning, data science, and education.
colab.google
colab이 무엇인지, 사용법에 대해서는 이 글에서는 생략하겠지만 간단히는 코드를 무료로 빠르게 실행시켜볼 수 있는 사이트라고 생각하시면 편합니다.
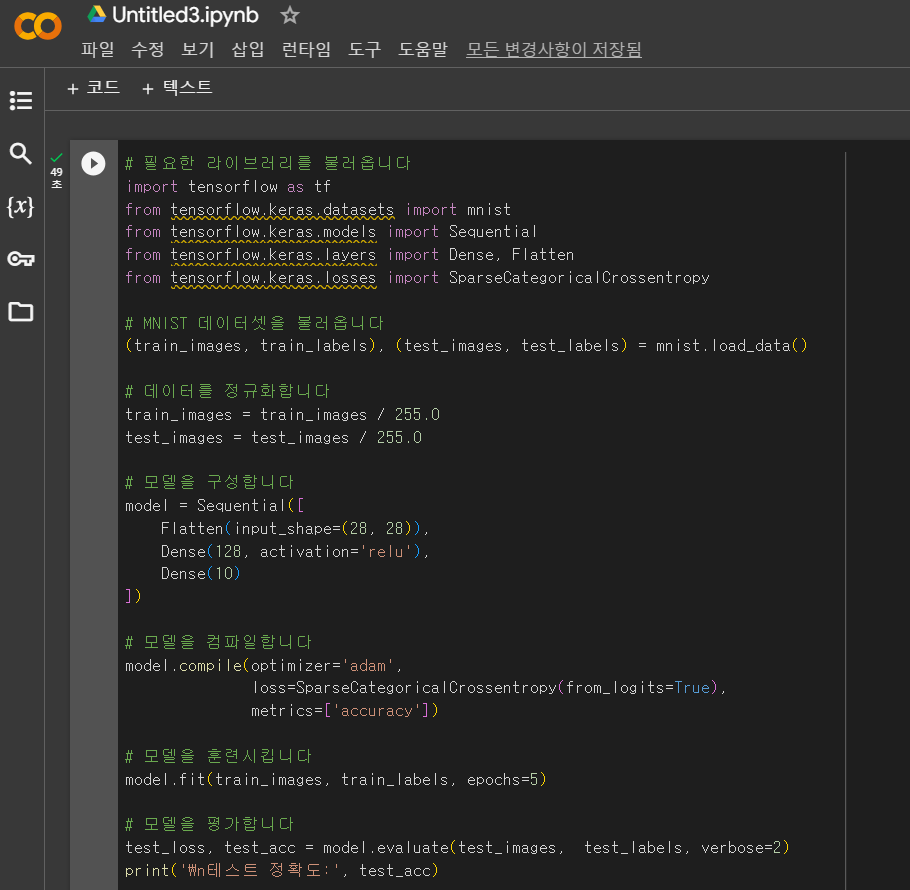
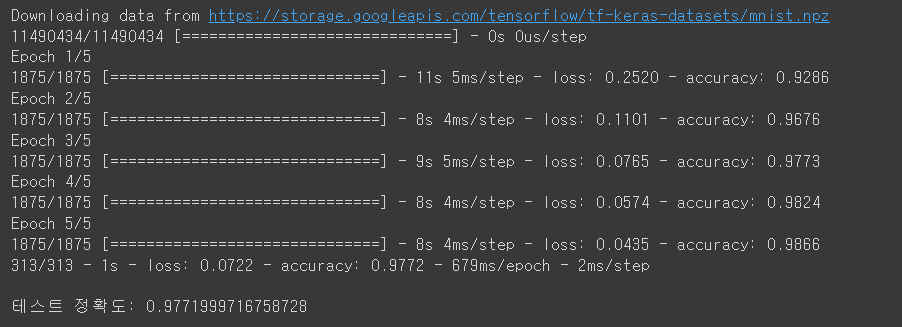
Colab 에 아까 복사한 코드를 붙여놓고 실행 (엔터)을 해보니 뭔가 돌아가다가 테스트 정확도라는 어떤 결과값이 나왔습니다.
정말 실행이 가능한 코드가 나왔네요!
분명 무언가를 분류하고 학습하고 테스트해서 나온 결과일텐데 도대체 무엇을 한건지 알 수가 없습니다.
코드 분석
딥러닝은 데이터 수집과 전처리 -> 모델 설계 -> 모델 훈련 -> 평가 및 튜닝 -> 활용 의 프로세스로 진행됩니다.
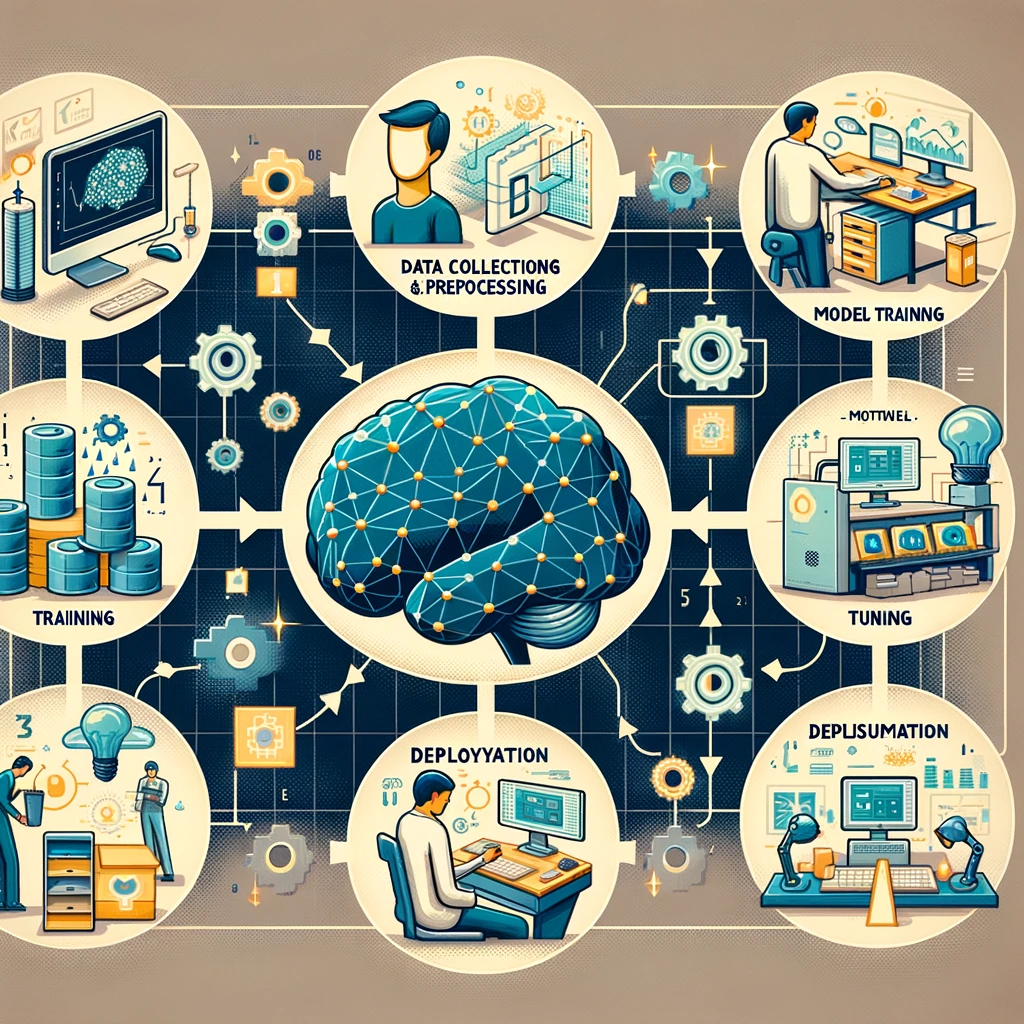
이제 위에 코드가 어떤 프로세스를 통해 딥러닝 모델을 구축하고 훈련시킨 것인지 알아보겠습니다.
( 코드에 활용된 함수 설명 포함)
1. 라이브러리 불러오기
TensorFlow는 머신러닝과 딥러닝 모델을 구축하고 훈련시키는 데 사용되는 라이브러리입니다.
tensorflow.keras는 TensorFlow의 일부로, 딥러닝 모델을 더 쉽게 구축하고 훈련할 수 있는 고수준 API를 제공합니다. Sequential, Dense, Flatten은 모델 구축에 사용되는 Keras의 레이어 클래스입니다.
SparseCategoricalCrossentropy는 분류 문제에 사용되는 손실 함수입니다.
2. MNIST 데이터셋 불러오기
MNIST 데이터셋은 손으로 쓴 숫자(0-9)의 28x28 픽셀 흑백 이미지로 구성되어 있습니다.
mnist.load_data()는 이 데이터셋을 불러와 훈련 세트
(train_images, train_labels)와 테스트 세트(test_images, test_labels)로 나눕니다.
3. 데이터 정규화
이미지의 픽셀 값은 0-255 사이의 정수입니다. 이 값을 0-1 사이의 실수로 변환하여 모델이 데이터를 더 잘 처리할 수 있도록 합니다.
4. 모델 구성
Sequential 모델은 레이어를 순차적으로 쌓는 방식의 간단한 모델입니다.
Flatten 레이어는 28x28 픽셀의 이미지를 784개의 픽셀 값이 있는 1차원 배열로 변환합니다.
첫 번째 Dense 레이어는 128개의 뉴런과 'relu' 활성화 함수를 가집니다.
두 번째 Dense 레이어는 10개의 출력 뉴런을 가지며, 각 뉴런은 하나의 숫자 클래스(0-9)를 나타냅니다.
5. 모델 컴파일
optimizer='adam'은 모델의 학습 과정을 관리하는 최적화 알고리즘입니다. loss=SparseCategoricalCrossentropy(from_logits=True)는 모델의 손실 함수로, 다중 클래스 분류 문제에 적합합니다. metrics=['accuracy']는 훈련과 평가 시 모델의 성능을 측정하는 데 사용됩니다.
6. 모델 훈련
model.fit() 함수는 훈련 데이터(train_images, train_labels)를 사용하여 모델을 훈련합니다.
epochs=5는 전체 훈련 데이터셋이 모델을 5번 통과하게 됨을 의미합니다.
7. 모델 평가
model.evaluate() 함수는 테스트 데이터셋(test_images, test_labels)을 사용하여 모델을 평가합니다.
평가 결과로 손실(test_loss)과 정확도(test_acc)를 출력합니다.
chatGPT가 코드도 작성해주고, colab을 통해 코드를 실행도 해볼 수 있는데
도통 내가 무엇을 하고 있는지 잘 이해가 되지는 않는 현실입니다.
아무래도 다음에는 눈높이를 좀 더 낮춰서 초등학생도 이해할 수 있는 쉬운 예제나 게임들을 만들어 봐야겠습니다.
'과학스토리' 카테고리의 다른 글
| 바이오플라스틱_친환경 미래를 위한 대안에 대하여 (76) | 2023.12.03 |
|---|---|
| 텔로미어_노화와 건강의 비밀 (64) | 2023.11.29 |
| 현대 과학에서의 엔트로피 개념정리 (59) | 2023.11.28 |
| 서울과학기술대_기계시스템디자인공학 교육과정 소개_향후 진로(실제 졸업생) (59) | 2023.11.27 |
| AGI(인공 일반 지능)은 어떻게 활용되는가 (49) | 2023.11.27 |



