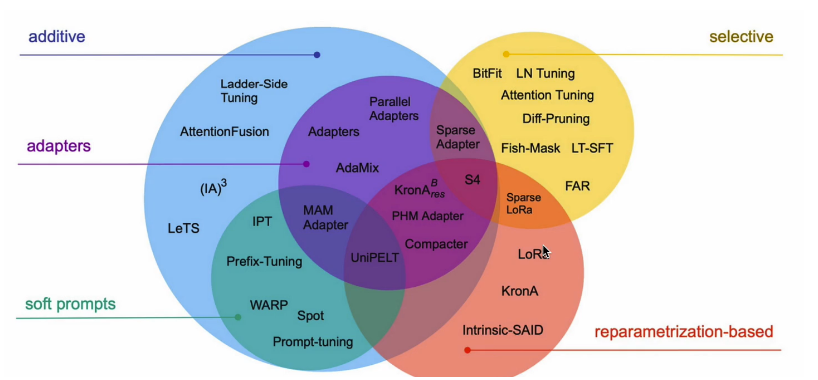
이 단계에서는 특히 모듈화한 작은 단위의 튜닝을 적용함으로써 리소스를 줄이고 높은 성능을 유지하는 효율성이 중요합니다.
이러한 방식을 PEFT (Parameter Efficiend Fine Tuning)이라고 부르기도 합니다.
PEFT 안에서도 또 다양한 모델들이 사용되고 있는데, 이 내용 또한 다음에 차근차근 알아보는 것으로!
9. RAG
RAG (Retrieval-augmented generation)이란, LLM의 내부 정보 표현을 보완하기 위해 외부 지식 소스에 모델을 기반으로 LLM 생성 응답의 품질을 향상시키기 위한 프레임워크를 말합니다.
ChatGPT를 사용해보신 분을 많이 아실텐데,
간혹가다가 이거 뭐 말도안되는 답변을 정말 그럴싸하게 하는 경우가 있습니다.
사용자가 깜박 속을 정도로 잘못된 정보를 정교하게 그럴싸한 문장으로 만드는데 알고보면 잘못된 정보인 경우가 있죠..
이러한 문제를 해결하기 위해 사용되는 방법이 RAG 입니다.
LLM에 미리 질문과 관련된 참고자료를 공급해주면, 그 안에서 답변을 찾는 방식으로 진행되기 때문에 기업 차원의 챗봇에 도입하기 쉬운 방식이기도 합니다.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
10. 자연어 처리
마지막 10번째는 자연어 처리 (Natural Language Processing, NLP)입니다.
자연어라는 것은 사람들 사이에서 발생하는 의사소통 언어를 말합니다.
기존의 컴퓨터는 입력된 딱딱한 언어만 사용 가능했지만, 정말 사람과 대화하는 느낌을 내기 위해서는 결국 컴퓨터도 사람이 사용하는 언어를 사용해야겠죠?
그래서 컴퓨터 언어를 정말 사람이 사용하는 언어로 바꾸는 과정을 자연어처리(NLP)라고 하며, 이러한 NLP를 자연스럽게 구사하기 위해 필요한 것이 LLM(거대언어모델) 입니다.
즉, LLM을 공부하기 위해 NLP가 필요한 것은 아니며 어떻게 보면 NLP를 하기 위해 필요한 것이 LLM이라고 볼 수도 있는데, 중요한 것은 NLP 기술이 AI 확산에 매우 중요한 역할을 하고 있다는 것입니다.
오픈소스가 발달하면서 AI는 사람이 텍스트로 작성한 입력값 문장에서 감정도 읽을 수 있는 수준으로 발달했고, 거기에 맞는 답변을 내놓을 수 있는 세상이 되었습니다.
앞으로 얼마나 더 자연스러워지느냐의 게임이 될 것이기 때문에 NLP 기술의 중요성은 뭐.. 더이상 설명하지 않아도 될 것 같습니다.
지금까지 작성한 10가지 항목을 모두 완벽히 이해해야만 무언가를 할 수 있는 것은 아닙니다.
LLM에 기반한 현재 기술들이 어떻게 개발되고 있는지 그 흐름을 대략 잡아가다 보면 왜 지금 있는 생성형 AI 프로그램들이 이상한 결과들을 내는지, 그리고 만일 내가 어떤 목적을 위해 챗봇 프로그램을 개발해야 한다면 어떤 것들을 위주로 개발해야 그 목적에 맞는 프로그램을 개발할 수 있는지 조금은 더 알 수 있지 않을까 싶습니다.
앞으로는 각 요소별로 조금 더 상세하게 들어가보기도 하고 가끔씩 쉬운 예제들도 풀어볼 수 있는 컨텐츠도 준비해보려 합니다.